阅读 AAPCS 笔记 —— 从寄存器到函数调用的 Arm 规范
AAPCS简介
AAPCS(Procedure Call Standard for Arm Architecture),Arm架构下的调用标准,用于描述汇编语言与C代码交互时的行为规范。这里提到的PCS,本质是Arm 架构 ABI(Application Binary Interface)的核心组成。如果目光仅放到Arm-M 系列MCU搭配C语言的开发的话,PCS几乎就是ABI的全部内容。
官方发布页
当前最新的aapcs32
延伸内容
一般来说,每个架构都有自己的PCS。有的时候一个架构可能会有多种调用约定,比如x86 (32位)曾经有cdecl、stdcall、fastcall、pascal 等多种调用约定;而x86-64 (64位)也有System V ABI(Linux、macOS)和Microsoft x64 Calling Convention(Windows)。由于Arm公司的强势与统一,Arm早早定义了全套标准的AAPCS,因此这对开发者更加友好。
C++的ABI兼容是另一个问题,需要单独讨论了。
AAPCS内容
以2025Q4的aapcs32 为例,先看目录,大致看看里面都包含了什么。
Contents
1 | Contents |
数据类型与对齐
基础数据类型
关于基础数据类型,主要的内容就是
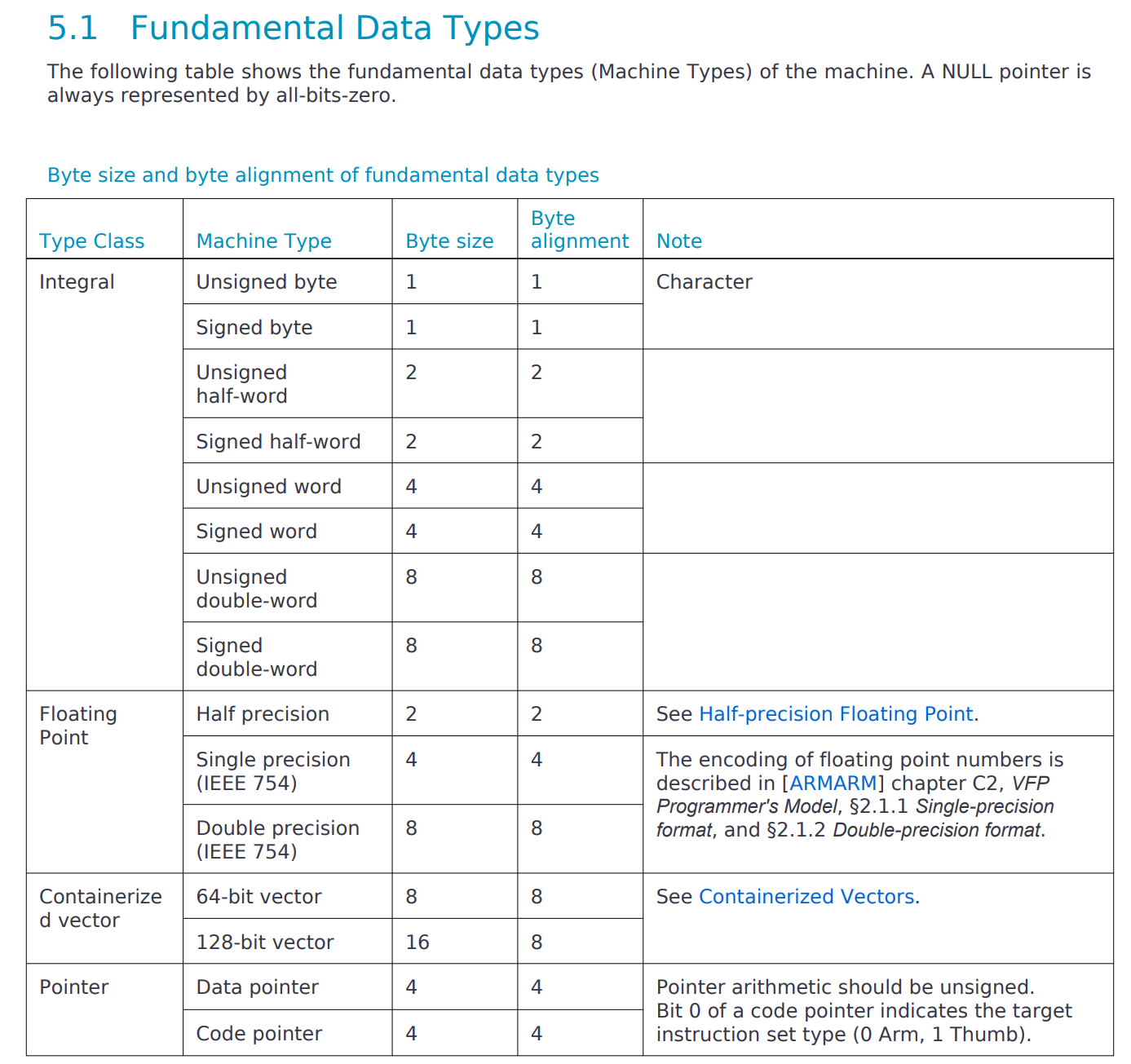
像整形、浮点型、指针这些都算比较常见的概念了,除此之外文档下面还单独提了一嘴半精度浮点数和容器化向量。
Arm架构支持三种半精度浮点数,IEEE754-2008、Arm替代格式、脑浮点数。前两种格式是互斥的,AAPCS的基础格式是IEEE754-2008,然后在调用过程中Arm替代格式也是允许的。
容器化向量的部分有点晦涩,跳过了。
字节序与字节顺序
这部分描述是这样的
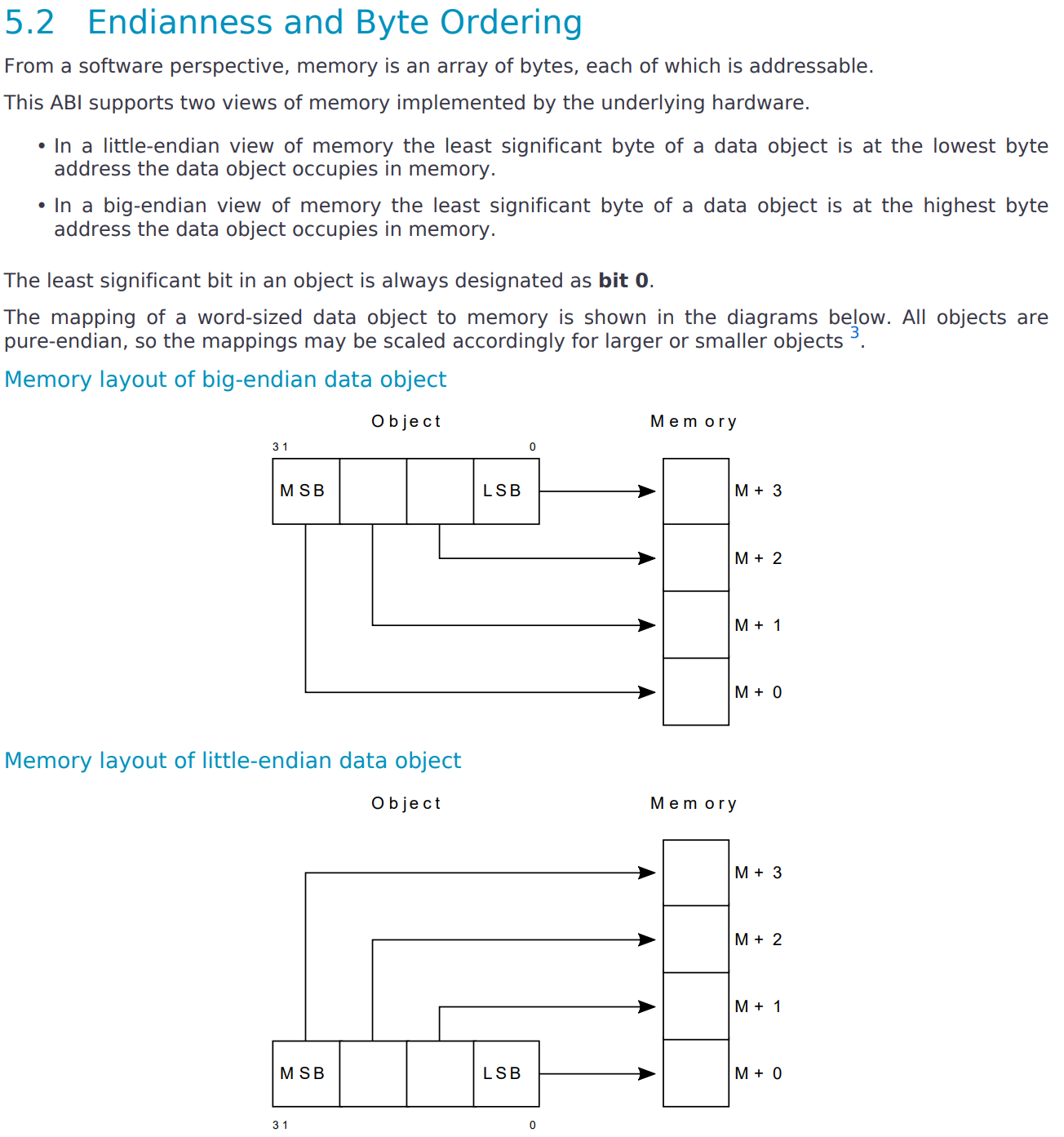
本质就是系统寻址的最小单元是字节,但是数据单元可能是由多个字节组成的,这样在表达的时候就会需要规则来约束一下,多个字节组成的数据哪边是高位哪边是低位。
复合数据类型
复合数据类型是一个或者多个基本数据类型组成的集合,而在过程调用中复合数据类型是被认为一个整体。复合类型可能包括:Aggregates(类似struct,成员在内存中顺序排列)、union(成员在内存中重叠排列)、array(成员在内存中重复排列)。
并且,这些定义是递归的;也就是说,每种类型都可以包含一个复合类型作为其成员。
- 对于复合变量成员的成员对齐,是指应用了任意语言修饰符之后的对齐方式。
- 对于复合变量成员的自然对齐,是指顶层成员的对齐方式的最大值,也就是对齐调整之前的值。
Aggregates
对于Aggregates,对齐方式应该为对齐度最高的组件的对齐方式。Aggregates实际的大小应该是其对齐方式的最小倍数,该倍数足以容纳其所有成员,前提是这些成员按照这些规则进行布局
Unions
Unions的对齐方式应为其对齐程度最高的成员的对齐方式。联合体的大小应为其对齐方式的最小倍数,该倍数足以容纳其最大的成员。
Arrays
Arrays的对齐方式应为其基类型的对齐方式。数组的大小应为其基类型的大小乘以数组中元素的数量。
Bit-fields
聚合体中作为基本数据类型的成员可以细分为位域;如果此类成员存在未使用的部分,且足以使后续成员以其自然对齐方式开始,则后续成员可以使用未分配的部分。为了计算聚合的对齐方式,成员的类型应为位域所基于的基本数据类型。聚合中位域的布局由相应的语言绑定定义
同构聚合
同构聚合是一种复合类型,其中构成该类型的所有基本数据类型都相同。同构性测试在数据布局完成后进行,并且不考虑访问控制或其他源语言限制。
如果由容器化向量类型组成的聚合的所有成员大小相同,即使容器化成员的内部格式不同,该聚合也被视为同构的。例如,一个包含 8 字节向量和一个 4 个半字向量的结构满足同构聚合的要求。
同构聚合具有一个基本类型,它是每个元素的基本数据类型。总大小是基本类型的大小乘以元素数量;其对齐方式与基本类型的对齐方式相同。
comment
这个部分其实是关于数据和内存的部分,倒是没有发现什么特别需要注意的内容。
基础过程调用标准
寄存器
寄存器又分为核心寄存器与协处理寄存器。
核心寄存器
原始的说法是这样的
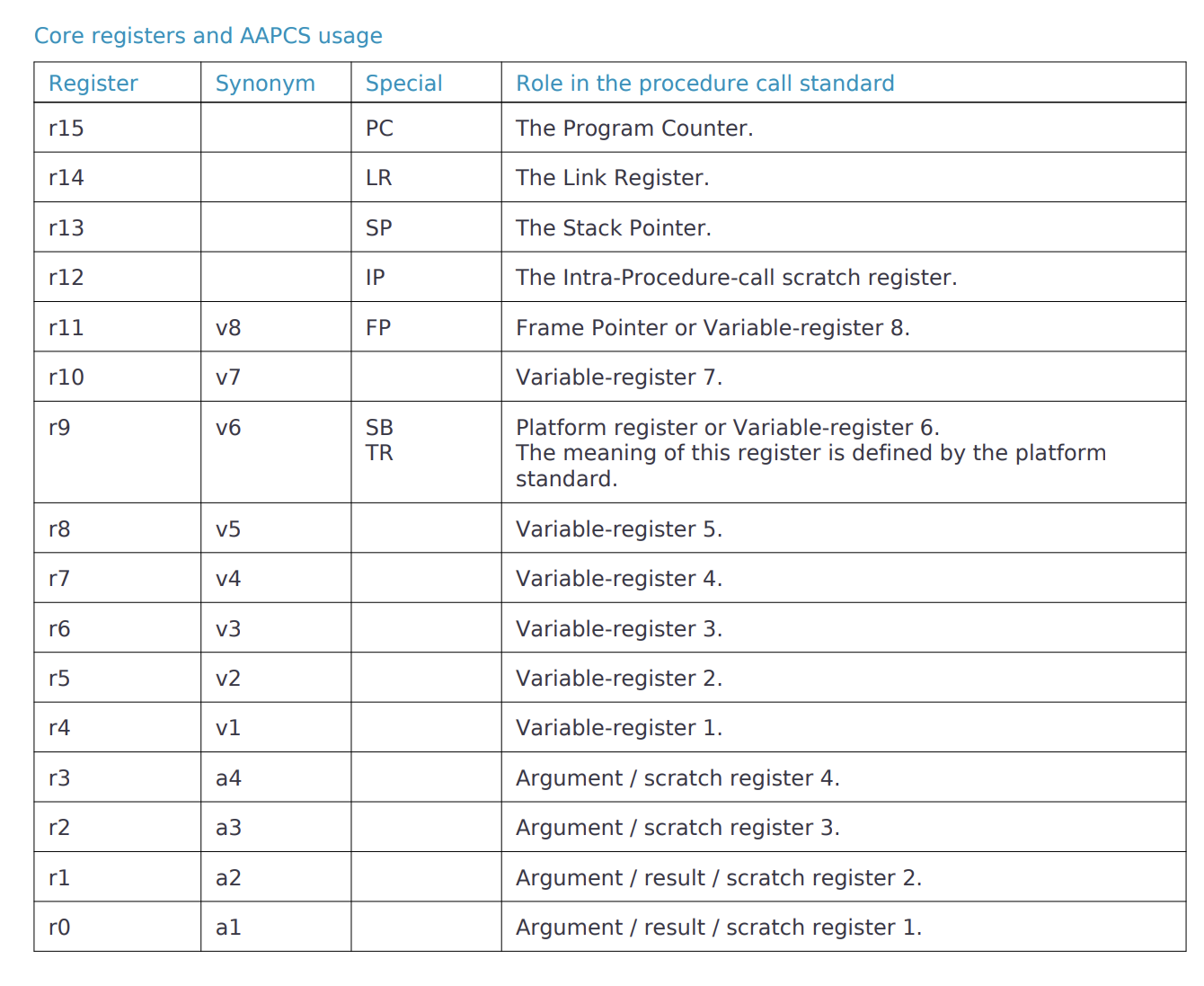
有16个32位寄存器r0 - r15,这些寄存器对于汇编是不区分大小写的,但是特定角色的寄存器使用大写的。除了这16个,还有一个状态寄存器CPSR。
对于纯的ASM代码来说,直接操作寄存器就可以,比如像R0-R8 可能地位都是平等的,没有什么特别的。但是一旦涉及到C与ASM的混合编程,就需要一些约定来实现互相的约定与识别。怎么来互联互通,那就是这个core register的用法,其实这里也是我找到这篇文档来阅读的动机了。
逐个过一下:
- R15(PC):这个是非常核心的寄存器了,它指示了当前程序运行到哪个指令。
- R14(LR):当前调用结束时,应该返回到哪里继续执行。
- R13(SP):栈指针,指示当前栈的使用状态
- R12(IP):过程内调用临时寄存器,用于远距离寻址与编译器临时使用。
- R4-R11 :寄存器,调用后需要恢复原样(R4-R8, R10, R11(v1-v5, v7-v8):调用后必须保持原样。R9 为 platform-specific,当被定义为 v6 时才需保存)
- R0-R3 : 寄存器,传递参数与返回值
对于一个典型的调用过程,存在调用方caller 与 被调用方callee。
- caller 在调用 callee 之前,会将callee 所需要的参数放置到R0-R3(如果参数超过了R0到R3的范围比如传8个参数,那前四个放R0到R3,后面的放栈里),然后LR 填caller 自己(BL的下一条指令),PC 填 callee(类似 BL callee)这样程序的控制权就转移给callee了。
- callee进入后,它可以按照约定的方式获取到自己所需的参数(R0-R3、栈),然后开展自己所需要的计算或者业务逻辑。如果在callee的业务中需要使用额外的寄存器,callee可以使用其他的寄存器,但是需要保证(R4-R11,SP)的数据被记录下来,在返回caller的时候,要保持原样。所以我们看汇编源码的时候,很多的汇编函数进来就把(R4-R11,SP)push到栈里,然后结束逻辑之后pop回原位就是这个道理。
- callee在做好现场保存后可以自由的使用R0-R11,SP来完成自己的业务,当运算结束现场也恢复后,通常是要给一个返回值的,而这个返回值一般是放到R0、R1里的。和参数传递类似,返回值传递也会有返回值超过R0、R1的场景,比如说返回值就是一个很大的数据结构,这种情况下R0、R1放不下,SP要保持现场没法往stack里塞,实际是怎么实施的呢?实际中这样的情况是由caller在调用callee之前分配出一块内存,然后将地址放到R0里,callee执行完将result填充一下就可以了。
- callee完成所有的一切,结束生命周期时,只要设置一下PC = LR,那程序控制权又转给caller了
从典型流程里不难看出,16个寄存器基本上都很忙碌,大家各司其职数据进进出出。但是IP好像和别人都不一样,它不涉及调用的参数传递、返回值传递,也不像PC、LR、SP有单独的职责,那IP是干啥的呢?
IP 的职责有几种:
- 远距离调用,Arm 的BL指令是有范围的,而超出范围的远距离寻址要依靠寄存器间接寻址。而其它寄存器各司其职都是没法用的,这个时候就可以用IP。
- 有的编译器会在函数入口做栈溢出检查,比如说,我知道callee中间会用100K stack,那我函数进来的时候就可以比较一下,SP - 100K < stack_limit ? ,这样不就可以知道是不是栈溢出了吗。那这个时候又出现了,其他寄存器各司其职,只有IP无牵无挂,那就用IP来。
- 总的来说就是,IP是没有职责的草稿纸,谁想用就用,但是也没有任何保证。
另外值得一提的是,R9 的定义是platform-specific的,只有被定为 v6 时才需保存。R4-R8、R10、R11、SP则是无条件保存。
CPSR也有一些自己的规则,这里跳过了。
上面提到的,如果参数或者返回值大于标准流程寄存器所表示的范围,可能会使用栈来传递参数,那么一个64 位的基础数据单元,算不算超过范围呢。
按照AAPCS的说法,对于超过32位的基础数据单元,如果是64位的也就是双字,可以使用两个连续寄存器,比如R0、R1或者R2、R3来传递,可以用一条单独的LDM从内存里取到数据。
对于128位的基础数据单元,也就是containerized vector,可以用4个连续的寄存器来传递,也是一条单独的LDM从内存load。
协处理器寄存器
VFP-v2协处理器有32个单精度寄存器,s0-s31,也可以作为16个双精度寄存器d0-d15访问(其中d0与s0、s1重叠;d1与s2、s3重叠;依此类推)。而其他的实现可能会增加更多的寄存器。比如VFP-v3 增加了16个双精度寄存器d16-d31,但是没有额外的单精度寄存器对应。
高级SIMD扩展和M型向量扩展 (MVE) 使用VFP寄存器集。高级SIMD扩展使用双精度寄存器表示64位向量,并进一步定义四字寄存器(q0与d0、d1重叠;q1与d2、d3重叠;依此类推)用于128位向量。MVE在相同的四字寄存器中使用128位向量。寄存器s16-s31(d8-d15, q4-q7)必须在子程序调用之间保持不变;寄存器s0-s15(d0-d7, q0-q3)无需保持不变(并且可以用于传递参数或在标准过程调用变体中返回结果)。寄存器 d16-d31(q8-q15),如果存在,也无需保持不变。FPSCR和VPR寄存器是唯一可能被符合规范的代码访问的状态寄存器。FPSCR和VPR又有各自的特点,但是跳过这里了。
过程、内存与栈
AAPCS适用于单个执行线程或进程(以下称为进程)。进程具有由底层机器寄存器和其可访问内存内容定义的程序状态。进程在执行过程中可访问的内存(而不会导致运行时错误)可能会有所变化。
一般,进程可以访问五种内存:
- 代码段,可读但不需要可写
- 只读静态段,只读
- 读写静态段,读写
- 堆
- 栈
读写静态段,又可被细分为已初始化、零初始化、未初始化。除了栈之外,其他的段都不要求内存单一连续。一个进程必须始终拥有一些代码和一个栈,但是其他类型的内存并非强制的。堆用于分配动态内存,而程序只应该执行代码段中的指令。
栈
stack是一个连续的内存区域,可以用来存储局部变量以及做调用的参数传递。stack是地址递减的,当前使用状态由SP(r13)来表示。通常来说,base 与 limit是用来描述stack的范围,一些时候limit是固定的,也有时候limit可以被动态调整。堆栈的维护规则包括通用规则与公共接口特定规则。
通用规则:
- Stack-limit ≤ SP ≤ stack-base
- SP mod 4 = 0
- 进程只在[SP, stack base - 1] 范围存储数据
类似
1 | ldmxx reg, {..., sp, ...} // reg != sp |
在遇到中断的时候,就是有可能违反第三条原则的。比如说SP被更改后中断进来,中断进来第一件事就是压栈保存现场,但是这个时候SP就是飞的,压栈就有可能压到别的位置。
公共接口规则:
- SP mod 8 = 0
所谓公共接口规则,就是在模块间边界。比如一个.o 暴露给外部可调用的符号。函数内部调用(inline、static)不算。为了更好的兼容性,公共接口要求更严格的对齐。任何时候SP都应该是4字节对齐的,也就是说栈只能4个字节4个字节的用。但是当进程调用的时候,需要把SP做成8字节对齐的。
实操的时候,尽量把一切按照严格的方法来。比如说,如果你要自己维护一个内存池,那别人从你这里分配内存的时候,你返回的就不能是按照4字节对齐来。关于栈探测,是为了防止悄悄爆栈所以在申请大的stack空间时,先逐页读一下,比如说应用申请1M的stack,那就拆成4K的步长,依次步进读一个字节,这样就可以避免静默的溢出。1
2
3
4
5
6
7struct Foo {
double a; // 需要 8 字节对齐
int b;
};
struct Foo *f = my_malloc(sizeof(struct Foo));
f->a = 3.14;
// 如果 my_malloc 返回 0x1004,a 的 offset = 0,但 0x1004 % 8 != 0 -> fault。因为f->a 可能用了STRD,而STRD无条件要求地址与传输大小对齐。
关于FP,也就是Frame Pointer,是用于调试和回溯的工具。当你想知道当前的程序是怎么一层层调进来的时候,FP可以帮助到你。每层调用在栈上放一个Frame Record(2个word),分别保存LR与前一个FP,这样就形成了一个调用链,而当前一个FP为0,调用链结束。
子调用
Arm 和 Thumb指令集都有一个BL指令,它就是将当前的BL的下一条指令放进LR,将callee放进PC。如果BL指令是Thumb的,那LR的首位将被置为1,Arm则为0.
链接器使用IP
Arm 和 Thumb的BL均无法实现完整的32位寻址,因此需要linker在caller 和 callee之间插入一个veneer。而插入的veneer需要保留除IP(r12)和条件码之外的所有寄存器内容。
返回值
返回值返回的方式取决于返回值的类型。
- 半精度浮点返回值(16位),会被返回到r0的LSB
- 小于4字节的基础数据类型会被返回到R0(零扩展或者符号扩展到一个字)
- 刚好4字节的基础数据类型会被返回到R0
- 双字也就是8字节的基础数据类型会被返回到R0与R1
- 128位也就是16字节的基础数据类型会被返回到R0到R3
- 不超过4字节的复合数据类型会返回到R0,其格式如该结果存储在字对齐的地址然后通过LDR读取到R0一致。R0中其它位的值为未指定的
- 大于4字节的复合数据类型,或者其大小无法由caller、callee静态确定的类型,将在内存中做返回值传递。该内存作为一个额外参数在调用时传递,并由callee在调用过程中修改。
参数传递
基本标准规定了在核心寄存器(r0-r3)和堆栈上传递参数。对于只接受少量参数的子程序,仅使用寄存器,从而大大减少调用开销。
参数传递被定义为一个两级的概念模型:
- 将源语言的参数映射到机器类型
- 将机器类型整理成最终的参数列表
从源语言到机器类型的映射对于每种语言都是固定的,并且是单独描述的。最终的结果将会是一个有序的参数列表。
后面有一些非常细节的参数处理过程,跳过了。
comment
这一章节其实是比较核心的内容,对典型场景的行为模式做了规范。
Ending
AAPCS 整体上还是比较底层视角的描述,有很多的细节是应用开发者所无需了解的。但是,尤其是在深度的问题排查时,来自AAPCS的一些说明可以帮助我们更好的理解汇编源码。小册子本身也不长,读完至少能看懂反汇编里的出入栈、参数传递、返回值的处理。