阅读 《ARM Cortex-M3 与 Cortex-M4 权威指南》 笔记 -- Part1
前言
对于MCU也就是微控制器而言,Arm cortex M系列的MCU几乎是市场里的标杆和模范生了。为了更深入的理解cortex M3/M4及这一类型的MCU,因此选择了《ARM Cortex-M3 与 Cortex-M4 权威指南》第三版,来做深入的学习。
这本书我在不同的渠道收到多次推荐,应该是业界非常有名的指导书了,希望能有满意的收获。
在学习的过程中,可能会借由实验来验证或者加深理解,实验会尽可能通过虚拟环境来做。
关于cortex M3、M4
Cortex M3、M4均由ARM公司设计,两者都是32位的微处理器,其中M3发布于2005、2006年,M4发布于2010年。两者的主要差异在于,M4处理器支持浮点运算并拥有更好的DSP性能。
ARM 文档中心
实验环境搭建
得益于前人的智慧,对于cortex M的交叉编译、模拟、调试都有比较成熟的方案了,我的实验平台是一个x86的debian小主机,会主要通过arm-none-eabi-gcc系列交叉编译;通过qemu做模拟;通过gdb-multiarch做调试。
使用工具的具体版本如下:
| 工具 | 版本 | 用途 |
|---|---|---|
qemu-system-arm |
7.2.22 | Cortex-M3/M4 机器模拟 |
arm-none-eabi-gcc |
12.2.1 | ARM 裸机交叉编译器 |
gdb-multiarch |
13.1 | 多架构 GDB 调试器 |
libnewlib-arm-none-eabi |
3.3.0 | 裸机 C 库 |
而对于实验code的基础布局如下:
1 | projects/01-env/ |
各自细节如:
1 | #Makefile |
1 | # linker.ld |
1 | // startup.c |
1 | //main.c |
1 | # debug.gdb |
Makefile 目标
| 目标 | 说明 |
|---|---|
make m3 |
编译 Cortex-M3 ELF |
make m4 |
编译 Cortex-M4 ELF |
make qemu-m3 |
直接运行 M3 (无调试) |
make qemu-m4 |
直接运行 M4 (无调试) |
make qemu-gdb-m3 |
M3 + GDB 等待连接 (:1234) |
make qemu-gdb-m4 |
M4 + GDB 等待连接 (:1234) |
make gdb |
连接 GDB 到 QEMU |
QEMU 机器选型
- Cortex-M3:
lm3s6965evb(TI Stellaris LM3S6965) - Cortex-M4:
mps2-an386(ARM MPS2 + AN386 FPGA)
两者均将代码映射到 0x00000000,SRAM 映射到 0x20000000,便于用同一套链接脚本。
- 如果希望使用其他机器,可以使用如下指令列出支持列表
1
qemu-system-arm -M help
实验环境验证
1 | # terminal 1: 启动 QEMU (等待 GDB) |
实验1:从 Reset 到 main——Cortex-M3 启动全流程跟踪
目标:结合反汇编与 GDB,完整跟踪 Cortex-M3 从上电复位到用户 main 函数执行的每一步,观察向量表布局、启动代码对 .bss 的初始化、函数调用时 LR 的变化,以及寄存器在循环中的活动。
前提:已完成环境搭建,能正常编译和启动 QEMU+GDB。
中断向量表与Reset_Handler
1 | # 编译M3的elf |
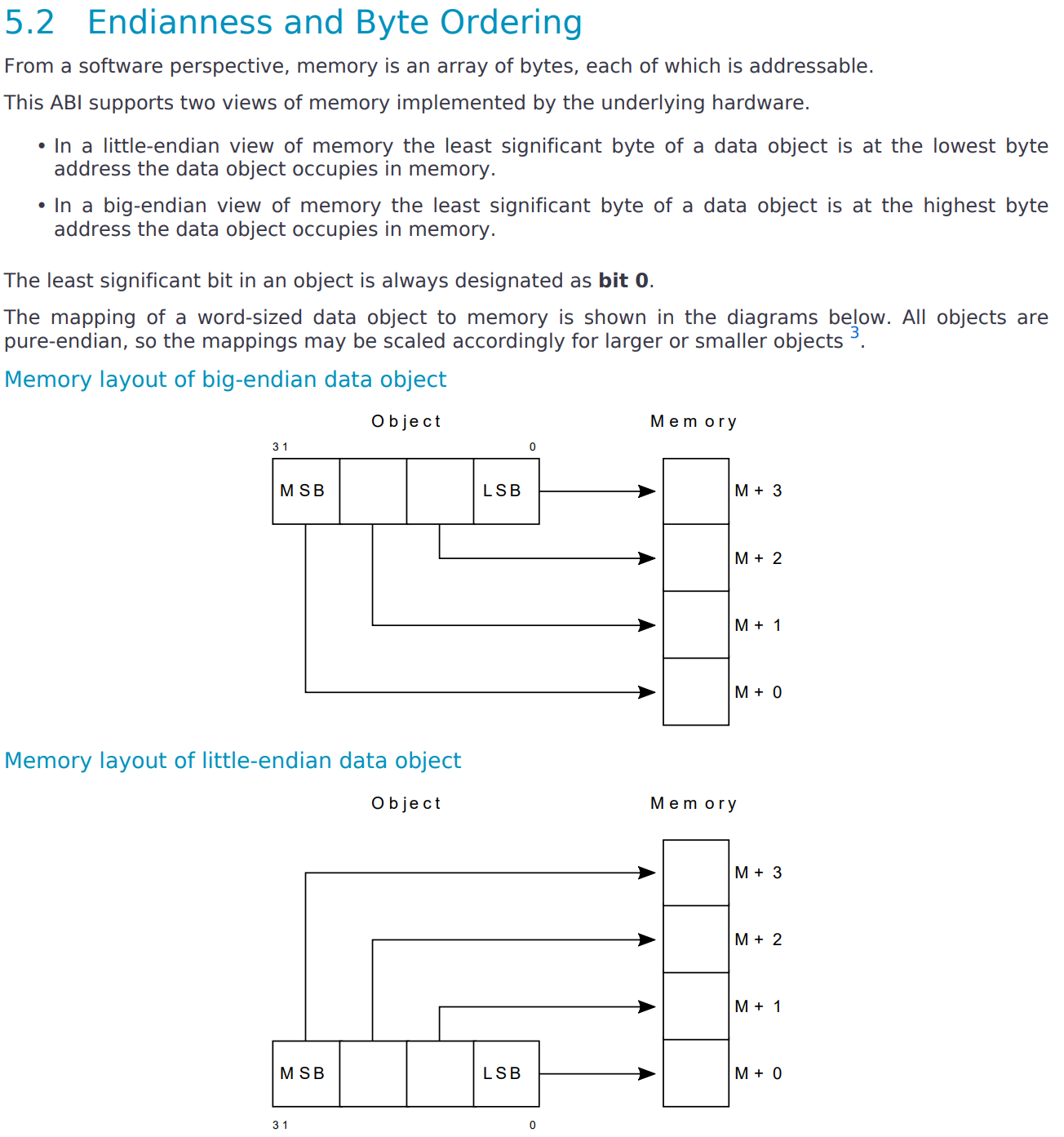
因为cortex-M3 是小端序的,所以实际这个表阅读方式是
| 偏移 | 值 (LE) | 对应异常 | 说明 |
|---|---|---|---|
0x0000 |
0x20010000 |
初始 MSP | 栈顶地址 |
0x0004 |
0x00000041 |
Reset_Handler | 地址 0x40,bit 0 = 1 (Thumb) |
0x0008 |
0x00000089 |
NMI_Handler | 地址 0x88 (= Default_Handler) |
0x000C |
0x00000089 |
HardFault_Handler | 同上,弱符号 alias |
0x002C |
0x00000089 |
SVC_Handler | |
0x0030 |
0x00000089 |
DebugMon_Handler | |
0x0038 |
0x00000089 |
PendSV_Handler | |
0x003C |
0x00000089 |
SysTick_Handler |
这里就是和我们startup.c里设置基本是对应的
1 | __attribute__((naked)) void Reset_Handler(void) { |
稍微有一点值得提出的是,这里的函数地址bit0都被置为1了,这是因为cortex-M要求Thumb模式,而在取出PC后,硬件是会自动清除bit0的。
关于Reset_Handler,startup.c里我们写的其实是:
1 | extern unsigned int _sdata, _edata, _sbss, _ebss; |
而我们通过反汇编,看一下实际编译生成的汇编代码其实是:
1 | arm-none-eabi-objdump -d test-m3.elf | grep -A 40 '<Reset_Handler>' |
1 | 00000040 <Reset_Handler>: |
代码并不算长,我们尝试解读一下
1 | 00000040 <Reset_Handler>: |
这里因为用到了链接脚本中的几个变量,这些变量的值也可以通过符号表二次确认:
1 | arm-none-eabi-objdump -t test-m3.elf | grep -E "counter|_s[bd]|_e[bd]|_sidata" |
能看出来,bss段唯一的一个4字节变量就是counter,所以Reset_Handler 也就是把它清零了。
通过GDB观察启动过程
两个终端,分别执行:
1 | make qemu-gdb-m3 |
1 | gdb-multiarch -q |
然后在弹出来的gdb交互式窗口分别执行:
1 | file test-m3.elf |
1 | gdb-multiarch -q |
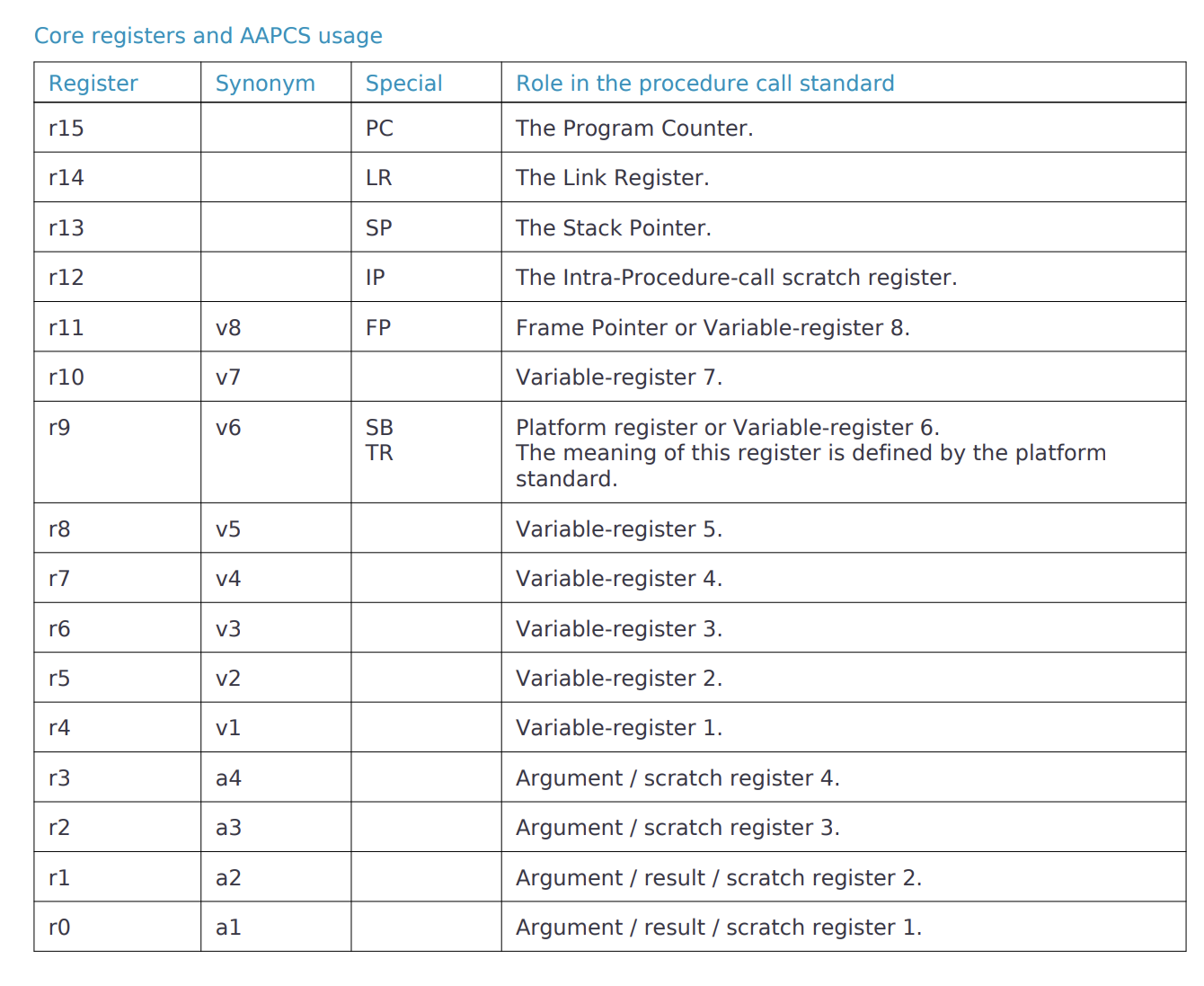
这里其实就能看到,PC在0x40表示Reset_Handler。SP在0x20010000,是我们设置的初始栈指针。LR指向0xffffffff,表示在Thread模式使用MSP。XPSR在0x41000000,其bit24为1表示运行在Thumb模式。
接下来,可以用内存dump工具来看向量表在内存的布局。
1 | (gdb) x/16xw 0x00000000 |
和objdump的是完全一致的。
- 建立自动显示,让每次stepi后自动刷新关键值接下来就可以stepi,一路单步执行下去
1
2
3
4display/i $pc
display/4xw 0x20000000
display $lr
display $r41
2
3
4stepi
stepi
stepi
stepireset 芯片,然后给程序的关键地址打上断点,重新观察流程1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42(gdb) display/i $pc
1: x/i $pc
=> 0x40 <Reset_Handler>: ldr r5, [pc, #48] @ (0x74 <Reset_Handler+52>)
(gdb) display/4xw 0x20000000
2: x/4xw 0x20000000
0x20000000 <counter>: 0x00000000 0x00000000 0x00000000 0x00000000
(gdb) display $lr
3: $lr = -1
(gdb) display $r4
4: $r4 = 0
(gdb) stepi
9 dst = &_sdata;
1: x/i $pc
=> 0x42 <Reset_Handler+2>: ldr r4, [pc, #52] @ (0x78 <Reset_Handler+56>)
2: x/4xw 0x20000000
0x20000000 <counter>: 0x00000000 0x00000000 0x00000000 0x00000000
3: $lr = -1
4: $r4 = 0
(gdb) stepi
10 while (dst < &_edata)
1: x/i $pc
=> 0x44 <Reset_Handler+4>: b.n 0x52 <Reset_Handler+18>
2: x/4xw 0x20000000
0x20000000 <counter>: 0x00000000 0x00000000 0x00000000 0x00000000
3: $lr = -1
4: $r4 = 536870912
(gdb) stepi
10 while (dst < &_edata)
1: x/i $pc
=> 0x52 <Reset_Handler+18>: ldr r3, [pc, #40] @ (0x7c <Reset_Handler+60>)
2: x/4xw 0x20000000
0x20000000 <counter>: 0x00000000 0x00000000 0x00000000 0x00000000
3: $lr = -1
4: $r4 = 536870912
(gdb) stepi
0x00000054 10 while (dst < &_edata)
1: x/i $pc
=> 0x54 <Reset_Handler+20>: cmp r4, r3
2: x/4xw 0x20000000
0x20000000 <counter>: 0x00000000 0x00000000 0x00000000 0x00000000
3: $lr = -1
4: $r4 = 5368709121
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19(gdb) monitor system_reset
(gdb) info registers
r0 0x0 0
r1 0x0 0
r2 0x0 0
r3 0x0 0
r4 0x0 0
r5 0xac 172
r6 0x0 0
r7 0x0 0
r8 0x0 0
r9 0x0 0
r10 0x0 0
r11 0x0 0
r12 0x0 0
sp 0x20010000 0x20010000
lr 0xffffffff -1
pc 0x42 0x42 <Reset_Handler+2>
xpsr 0x41000000 10905190401
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65(gdb) break *0x58
Breakpoint 1 at 0x58: file startup.c, line 13.
(gdb) break *0x5c
Breakpoint 2 at 0x5c: file startup.c, line 15.
(gdb) break *0x62
Breakpoint 3 at 0x62: file startup.c, line 15.
(gdb) break *0x6a
Breakpoint 4 at 0x6a: file startup.c, line 17.
(gdb) break main
Breakpoint 5 at 0x94: file main.c, line 4.
(gdb) continue
Continuing.
Breakpoint 1, Reset_Handler () at startup.c:13
13 dst = &_sbss;
1: x/i $pc
=> 0x58 <Reset_Handler+24>: ldr r4, [pc, #36] @ (0x80 <Reset_Handler+64>)
2: x/4xw 0x20000000
0x20000000 <counter>: 0x00000000 0x00000000 0x00000000 0x00000000
3: $lr = -1
4: $r4 = 536870912
(gdb) continue
Continuing.
Breakpoint 2, Reset_Handler () at startup.c:15
15 *dst++ = 0;
1: x/i $pc
=> 0x5c <Reset_Handler+28>: mov r3, r4
2: x/4xw 0x20000000
0x20000000 <counter>: 0x00000000 0x00000000 0x00000000 0x00000000
3: $lr = -1
4: $r4 = 536870912
(gdb) continue
Continuing.
Breakpoint 3, 0x00000062 in Reset_Handler () at startup.c:15
15 *dst++ = 0;
1: x/i $pc
=> 0x62 <Reset_Handler+34>: str r2, [r3, #0]
2: x/4xw 0x20000000
0x20000000 <counter>: 0x00000000 0x00000000 0x00000000 0x00000000
3: $lr = -1
4: $r4 = 536870916
(gdb) continue
Continuing.
Breakpoint 4, Reset_Handler () at startup.c:17
17 main();
1: x/i $pc
=> 0x6a <Reset_Handler+42>: bl 0x90 <main>
2: x/4xw 0x20000000
0x20000000 <counter>: 0x00000000 0x00000000 0x00000000 0x00000000
3: $lr = -1
4: $r4 = 536870916
(gdb) continue
Continuing.
Breakpoint 5, main () at main.c:4
4 counter = 0;
1: x/i $pc
=> 0x94 <main+4>: ldr r3, [pc, #16] @ (0xa8 <main+24>)
2: x/4xw 0x20000000
0x20000000 <counter>: 0x00000000 0x00000000 0x00000000 0x00000000
3: $lr = 111
4: $r4 = 536870916
在这样的流程里,基本上观察到了启动过程里cpu的行为。
To Be Continued
要学习和记录的内容比较多,先来一篇博文记录最开始的内容,后续会随着阅读的深入对各重点内容加以记录与实验。
感谢阅读~